自注意力机制与Transformer(二)
自注意力机制与Transformer(二)
1.编码器(Encoder)
把输入序列(如词向量序列)编码成一组上下文相关的特征向量,供解码器使用。
一个 Encoder 由 N 层(通常为 6 层) 堆叠而成。
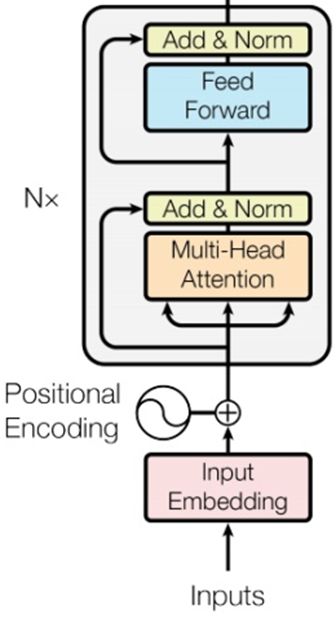
每一层包含两个子层:
-
多头自注意力层(Multi-Head Self-Attention)
-
前馈全连接层(Feed Forward Network)
每个子层都有:
- 残差连接(Residual Connection)
- 层归一化(LayerNorm)
1.1数据流动(单层示意)
1.2编码器自注意力的特点
- 输入序列中的每个词都可以关注(attend)序列中其他所有词;
- 这是双向注意力(bidirectional attention);
- 能捕捉全局语义依赖。
2.解码器(Decoder)
一个 Decoder 也由 N 层堆叠,每层包含 三个子层:
-
Masked 多头自注意力(Masked Multi-Head Self-Attention)
-
交叉注意力(Cross-Attention)旧称:编码器-解码器注意力(Encoder-Decoder Attention)
Encoder–Decoder Attention 是历史命名;Cross-Attention 是机制级泛化命名。
Cross-Attention(泛化称呼)
- 包括但不限于:
- 文本 ↔ 图像
- 动作 ↔ 状态
- 音频 ↔ 文本
- 任何 Q ≠ K/V 的 Attention
- 包括但不限于:
-
前馈全连接层(Feed Forward Network)
上下两部分与Encoder相同,多了中间与Encoder输出(Memory)进行交互的部分,即“Encoder-Decoder attention”。 这部分的输入,Q来自于下面多头注意力机制的输出,K和V均是Encoder部分的输出(Memory)经过线性变换后得到。这样设计也是在模仿传统 Encoder-Decoder 模型的解码过程。
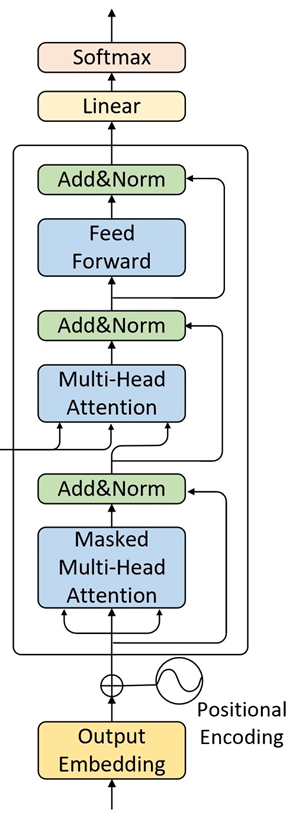
同样,每个子层后都有:
- 残差连接
- 层归一化
2.1数据流动(单层示意)
2.1各层注意力的作用
| 子层 | 注意力类型 | 说明 |
|---|---|---|
| ① Masked Self-Attention | 只看过去的词(防止看到未来) | 保证自回归生成 |
| ② Cross-Attention (Encoder-Decoder Attention) |
Query 来自 Decoder,Key/Value 来自 Encoder 输出 | 让解码器“看见”输入序列的语义 |
| ③ Feed Forward | 非线性映射 | 提高表达能力 |
2.3为什么 Decoder 要 Mask?
在训练生成任务时(如翻译、对话、语言建模):
第 i 个词的预测只能依赖于前 i−1 个词,不能“偷看未来”。
Masked Self-Attention 就是通过在注意力矩阵上添加一个“下三角掩码(mask)”,
把未来位置的权重设为 ,从而屏蔽它们的影响。
在 Masked Self-Attention 中,我们在 softmax 前加一个 mask 矩阵 :
其中:
- 表示允许关注
- 表示禁止关注(softmax 后变成 0)
对于一个长度为 4 的序列,mask 矩阵 是一个 下三角矩阵:
这样:
- 第 1 个词只能看自己;
- 第 2 个词能看第 1、2 个;
- 第 3 个词能看第 1、2、3 个;
- 第 4 个词能看第 1、2、3、4 个。
3.Encoder-Decoder 信息交互(Cross-Attention实现的)
-
Encoder 输出一系列语义向量(每个词一个);
-
Decoder 在第二个注意力层中:
-
以 Decoder 自己的隐藏状态为 Query;
-
以 Encoder 的输出为 Key / Value;
-
实现跨模态的信息融合(语言理解 → 语言生成)。
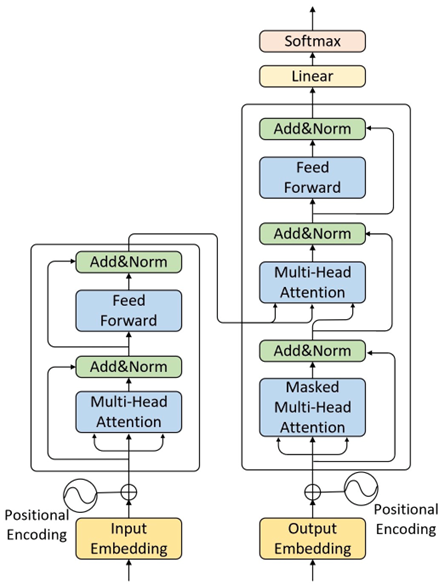
4.对比
| 特征 | 编码器 (Encoder) | 解码器 (Decoder) |
|---|---|---|
| 输入 | 原始序列(如源语言句子) | 已生成的目标序列 |
| 注意力类型 | 自注意力(可看全部) | Masked 自注意力 + 编码器-解码器注意力 |
| 是否 Mask | ❌ 否 | ✅ 是(防止看未来) |
| 输出 | 语义特征序列 | 生成下一个 token 的概率分布 |
| 应用示例 | BERT、ViT(只用编码器) | GPT(只用解码器) |
| 同时使用 | 完整 Transformer(翻译模型) | Encoder + Decoder 一起 |