线性回归
1.线性回归模型
回归 (regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
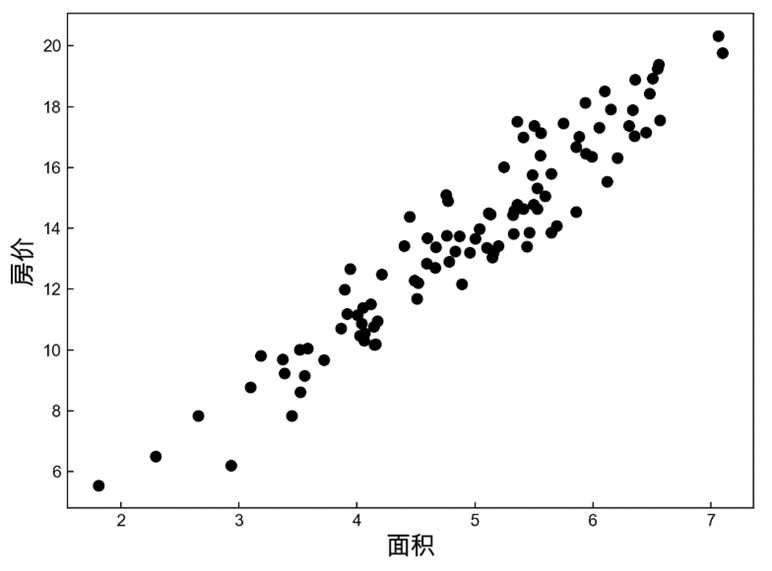
以房价预测为例, 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。
在机器学习的术语中,该数据集称为训练数据集 (training data set) 或训练集 (training set)。 每行数据(比如一次房屋交易相对应的数据)称为样本 (sample), 也可以称为数据点 (data point)或数据样本 (data instance)。 我们把试图预测的目标(比如预测房屋价格)称为标签 (label)或目标 (target)。预测所依据的自变量(面积和房龄)称为特征 (feature)或协变量 (covariate)。
某些情况下,其它因素同样也能影响房屋价格。如到房屋学校、医院和到商场的距离等,所以这时便有了影响房价的4个因素,而在机器学习中将其称为特征(Feature)或属性(Attribute),因此,包含多个特征的线性回归就叫作多变量线性回归(Multiple Linear Regression)。
数学表达式为:
y ^ = w 1 x 1 + w 2 x 2 + ⋯ + w d x d + b \hat{y} = w_1 x_1 + w_2 x_2 + \cdots + w_d x_d + b
y ^ = w 1 x 1 + w 2 x 2 + ⋯ + w d x d + b
或者用向量形式更简洁地表示:
y ^ = w ⊤ x + b \hat{y} = \mathbf{w}^\top \mathbf{x} + b
y ^ = w ⊤ x + b
其中:
x ∈ R d \mathbf{x} \in \mathbb{R}^d x ∈ R d
w ∈ R d \mathbf{w} \in \mathbb{R}^d w ∈ R d
b ∈ R b \in \mathbb{R} b ∈ R
y ^ \hat{y} y ^
给定训练数据特征𝐗和对应的已知标签𝐲, 线性回归的目标是找到一组权重向量𝐰和偏置𝑏: 当给定从𝐗的同分布中取样的新样本特征时, 这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。
虽然我们相信给定x \mathbf{x} x y y y n n n 1 ≤ i ≤ n 1 \leq i \leq n 1 ≤ i ≤ n y ( i ) y^{(i)} y ( i ) w ⊤ x ( i ) + b \mathbf{w}^\top \mathbf{x}^{(i)}+b w ⊤ x ( i ) + b X \mathbf{X} X y \mathbf{y} y
在开始寻找最好的模型参数 (model parameters)𝐰 𝐰 w 𝑏 𝑏 b
(1)一种模型质量的度量方式;
(2)一种能够更新模型以提高模型预测质量的方法。
2.损失函数
在我们开始考虑如何用模型拟合 (fit)数据之前,我们需要确定一个拟合程度的度量。在线性回归中,我们的目标是让预测值尽可能接近真实值 。但是「接近」这个概念需要量化 ——因此我们需要一个数学指标来衡量模型预测的“好坏”,这就是损失函数 (Loss Function)。
损失函数越小,说明模型预测越准确。
2.1均方误差
回归问题中最常用的损失函数是平方误差函数。当样本i i i y ^ ( i ) \hat{y}^{(i)} y ^ ( i ) y ( i ) y^{(i)} y ( i )
单个样本的损失:
ℓ ( y ^ , y ) = 1 2 ( y ^ − y ) \ell(\hat{y}, y) = \frac{1}{2}(\hat{y} - y)
ℓ ( y ^ , y ) = 2 1 ( y ^ − y )
其中:
y ^ \hat{y} y ^
y y y
系数 1 2 \frac{1}{2} 2 1
所有样本的平均损失:
L ( w , b ) = 1 n ∑ i = 1 n 1 2 ( y ^ ( i ) − y ( i ) ) 2 = 1 2 n ∑ i = 1 n ( ( w ⊤ x ( i ) + b ) − y ( i ) ) \mathcal{L}(w, b) = \frac{1}{n} \sum_{i=1}^{n} \frac{1}{2}(\hat{y}^{(i)} - y^{(i)})^2 = \frac{1}{2n}\sum_{i=1}^n \left( (\mathbf{w}^\top \mathbf{x}^{(i)} + b) - y^{(i)} \right)
L ( w , b ) = n 1 i = 1 ∑ n 2 1 ( y ^ ( i ) − y ( i ) ) 2 = 2 n 1 i = 1 ∑ n ( ( w ⊤ x ( i ) + b ) − y ( i ) )
其中:
n n n
x ( i ) x^{(i)} x ( i )
w w w
y ( i ) y^{(i)} y ( i )
y ̂^{(i)} 是第i个房屋的预测价格。
当L L L w ̂ 和{ b ̂ } 就是要求的目标参数。当L L L h ( x ) h(x) h ( x ) L L L L L L
优缺点
优点:
平滑、连续、可微;
对误差有“放大效应”,有助于优化;
解析上容易推导梯度。
缺点:
替代方案:
MAE(平均绝对误差):∣ y ^ − y ∣ |\hat{y}-y| ∣ y ^ − y ∣
Huber 损失:结合 MSE 与 MAE 的优点。
3.神经网络
3.1单层神经网络
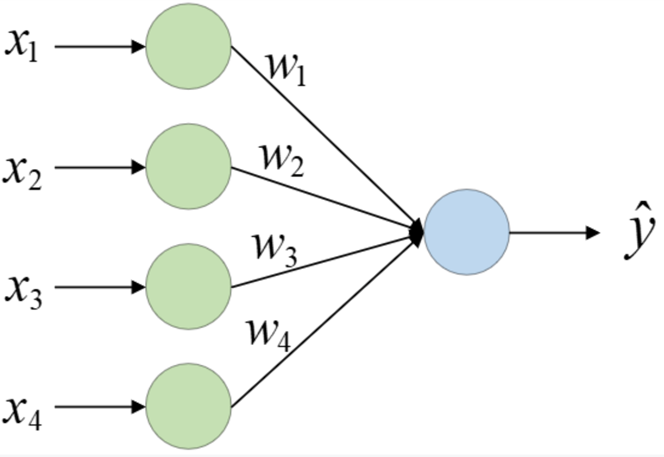
上面是一个简单的神经网络结构图,每个圈表示一个神经元(Neuron),输入层神经元个数表示样本特征维度,输出层神经元的个数表示输出维度。尽管这里有输入层(第0层)和输出层(第1层)两层,但在一般情况下只将含有参数(权重、偏置)的层称为一个网络层,因此线性回归模型是一个单层的神经网络。
图示的网络结构中,输出层和输入层的所有神经元都是完全连接的。如果某一层每个神经元的输入都完全依赖于上一层所有神经元的输出,则将该层称作是一个全连接层(Fully-connected Layer)。或者稠密层(Dense Layer)。上图的输出层就是一个全连接层。
3.2深度神经网络
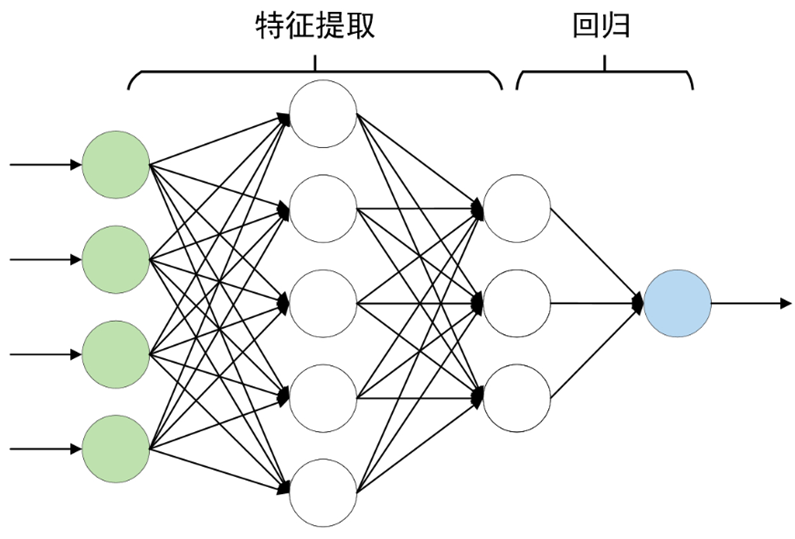
深度神经网络(Deep Neural Network, DNN)也叫做深度前馈神经网络(Deep Forward Neural Network)一般是指网络网络层数大于2的神经网络,如图所示便是一个简单的深度神经网络,其有3个全连接层。同时,将输入层与输出层之间的所有层都称为隐藏层或隐含层(Hidden Layer)。
对于输出层之前的所有层,都可以将其看成是一个特征提取的过程,而且越靠近输出层的隐含层也就意味着提取得到的特征越抽象。当原始输入经过多层网络的特征提取后,就可以将提取得到的特征输入到最后一层进行相应的操作(分类或者回归等)。
4.线性回归简洁实现
4.1 nn.Linear()使用
如图所示,对于每个网络层来说均是一个全连接层。例如对于第1个全连接层来说,其输入维度(神经元的数量)为4,输出维度为5,即由5个线性组合构成了该全连接层。同时nn.Linear()已经在内部随机初始化了网络层对应的权重参数。此时可以通过如下方式来定义该全连接层,示例代码如下所示:
1 2 import toprch.nn as nn4 ,5 )
第1行导入torch中的nn模块。第2行定义一个全连接层且nn.Linear()内部已经随机初始化了网络层对应的权重。同理对于第2个全连接层来说定义方式为nn.Linear(5, 3)。
通过如下方式来完成一次全连接层的计算,示例代码如下所示:
1 2 3 4 5 def test_linear ():1. ,2 ,3 ,4 ],[4 ,5 ,6 ,7 ]])4 ,5 )
第2行表示定义输入样本,形状为[2,4]列,即样本数量为2,特征数量为4。第4行则是计算该全连接层对应的结果,输出形状为[2,5]。
4.2 nn.Sequential()使用
此时已经知道了如何定义一个全连接层,并完成计算,但图中有多个全连接层,此时可以将所有网络层放入到一个有序容器中一次完成整个计算过程,示例代码如下:
1 2 3 4 5 def multi_layers_sequential ():1. ,2 ,3 ,4 ],[5 ,6 ,7 ,8 ]], dtype=torch.float32)4 ,5 ),nn.Linear(5 ,3 ),nn.Linear(3 ,1 ))print (y)
4.3 nn.MSELoss使用
在定义好一个模型之后便需要通过最小化对应的损失函数来求解得到模型对应的权重参数。在此处可以通过计算预测值与真实值之间的均方误差来构造损失函数。在PyTorch中,可以借助nn.MSELoss()来实现这一目的。
1 2 3 4 5 6 7 8 def test_loss ():1 ,2 ,3 ],dtype=torch.float32)2 ,2 ,1 ],dtype=torch.float32)0.5 * torch.mean((y-y_hat)**2 )'mean' )print (l1,l2)
第2-3行定义真实值和预测值这两个张量。第4行表示自行实现损失计算。第5~6行借助PyTorch中nn.MSELoss()来实现,其中reduction='mean’表示返回均值,而reduction='sum’表示返回和。
MSE 本身已经包含了“平方”和“平均” ,不需要再乘以 0.5 。只有在某些优化场景(如配合 L2 正则或特定梯度推导)中,才会使用 0.5 * MSE 来简化导数(因为平方的导数是 2x,乘 0.5 后变成 x),但此时也必须先平方再平均。
4.4房价预测实现
第6~7行表示将其转换为PyTorch中的张量,且指定类型为浮点型。第8行表示返回测试数据,两者的形状均为[100,1]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import numpy as npimport torchimport torch.nn as nnimport matplotlib.pyplot as plt""" 1.构建数据集 随机产生100个样本点并加入相应的噪声,其中x表示房屋面积,y表示房屋价格。 """ def make_house_data ():""" 构造数据集 :return: x:shape [100,1] y:shape [100,1] """ 20 ) 100 , 1 ) + 5 100 , 1 ) 2.8 - noise """ 表示将其转换为PyTorch中的张量,且指定类型为浮点型。 """ return x, y """ 可视化函数 """ def visualization (x, y, y_pred=None ):'ytick.direction' ] = 'in' 'xtick.direction' ] = 'in' '面积' , fontsize=15 ) '房价' , fontsize=15 )'black' ) 'font.sans-serif' ] = ['Arial Unicode MS' ]def train (x, y ):40 0.003 1 ] 1 """ 定义随机梯度下降优化器来求解模型,其中net.parameters()表示得到容器中所有网络层 对应的参数,lr表示执行梯度下降时的学习率。 """ """ 迭代求解网络中的权重参数,即训练过程。 """ for epoch in range (epochs):print ("Epoch: {}, loss: {}" .format (epoch, l))""" 则是根据训练完成的模型来对房价进行预测。 """ print ("RMSE: {}" .format (torch.sqrt(l / 2 )))return logits.detach().numpy()if __name__ == '__main__' :
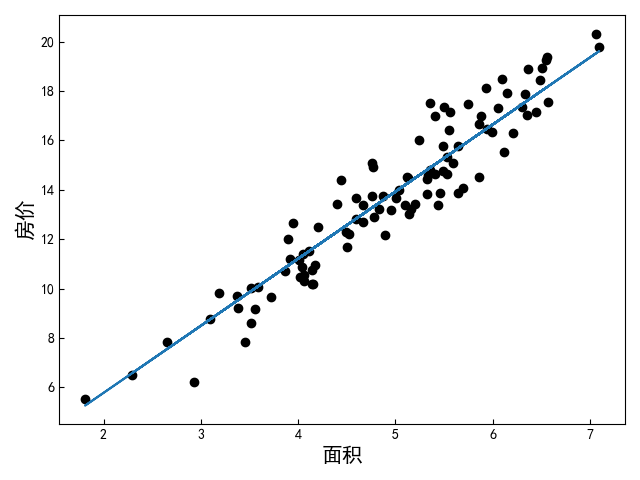
图中圆点表示原始样本,直线表示根据输入面积预测得到的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 Epoch : 0 , loss: 279 .0893249511719 Epoch : 1 , loss: 197 .5123291015625 Epoch : 2 , loss: 139 .86776733398438 Epoch : 3 , loss: 99 .1345443725586 Epoch : 4 , loss: 70 .3512954711914 Epoch : 5 , loss: 50 .01227569580078 Epoch : 6 , loss: 35 .640159606933594 Epoch : 7 , loss: 25 .484416961669922 Epoch : 8 , loss: 18 .308088302612305 Epoch : 9 , loss: 13 .237091064453125 Epoch : 10 , loss: 9 .653782844543457 Epoch : 11 , loss: 7 .121710300445557 Epoch : 12 , loss: 5 .332477569580078 Epoch : 13 , loss: 4 .068147659301758 Epoch : 14 , loss: 3 .174736261367798 Epoch : 15 , loss: 2 .5434224605560303 Epoch : 16 , loss: 2 .097313642501831 Epoch : 17 , loss: 1 .7820767164230347 Epoch : 18 , loss: 1 .559316873550415 Epoch : 19 , loss: 1 .4019043445587158 Epoch : 20 , loss: 1 .2906664609909058 Epoch : 21 , loss: 1 .2120589017868042 Epoch : 22 , loss: 1 .1565083265304565 Epoch : 23 , loss: 1 .1172503232955933 Epoch : 24 , loss: 1 .0895051956176758 Epoch : 25 , loss: 1 .0698949098587036 Epoch : 26 , loss: 1 .0560336112976074 Epoch : 27 , loss: 1 .0462342500686646 Epoch : 28 , loss: 1 .039305329322815 Epoch : 29 , loss: 1 .0344047546386719 Epoch : 30 , loss: 1 .0309374332427979 Epoch : 31 , loss: 1 .0284826755523682 Epoch : 32 , loss: 1 .026743769645691 Epoch : 33 , loss: 1 .025510549545288 Epoch : 34 , loss: 1 .0246347188949585 Epoch : 35 , loss: 1 .024011492729187 Epoch : 36 , loss: 1 .023566484451294 Epoch : 37 , loss: 1 .0232475996017456 Epoch : 38 , loss: 1 .0230181217193604 Epoch : 39 , loss: 1 .0228509902954102 RMSE : 0 .7150974869728088
参考
1.王成、黄晓辉《跟我一起学深度学习》
2.李沐-《动手学深度学习》