逻辑回归到Softmax回归
逻辑回归到Softmax回归
1.分类问题
一个新算法的诞生要么用来改善已有的算法模型,要么就是首次提出用来解决一类新的问题,而逻辑回归模型恰恰属于后者,它是用来解决一类新的问题——分类(Classification)。什么是分类问题呢?
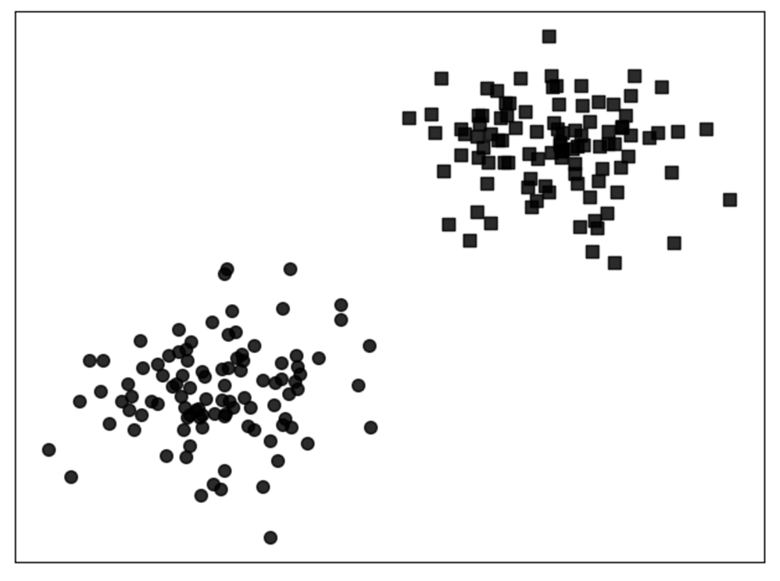
现在有两堆样本点,需要建立一个模型来对新输入的样本进行预测,判断其应该属于哪个类别,即二分类问题(Binary Classification),如图所示。线性回归解决不了,那么我们可不可以在此基础上做一点改进以实现分类的目的呢?
2.逻辑回归模型
可以通过建立一个模型用来预测每个样本点属于其中一个类别的概率,如果就可以认为该样本点属于这个类别,这样就能解决上述的二分类问题了。该怎样建立这个模型呢?在线性回归中,我们的输出可能是任意实数,但此处既然要得出一个样本所属类别的概率最直接的办法就是,通过一个函数 ,将和这两个特征的线性组合映射至[0,1]的范围。由此便得到了逻辑回归中的预测模型:
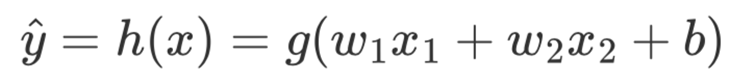
其中,同样为Sigmoid函数;和为未知参数;称为假设函数(Hypothesis),当大于某个值(通常设为0.5)时,便可以认为样本属于正类,反之则认为属于负类。同时,也将称为两个类别间的决策边界(Decision Boundary)。当求解得到和b后,也就意味着得到了这个分类模型。
如果该数据集有个特征维度,那么同样只需要将所有特征的线性组合映射至区间 [0,1] 即可
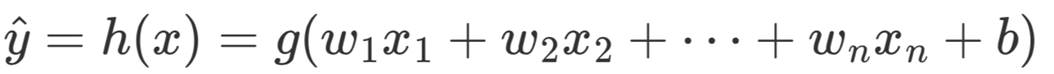
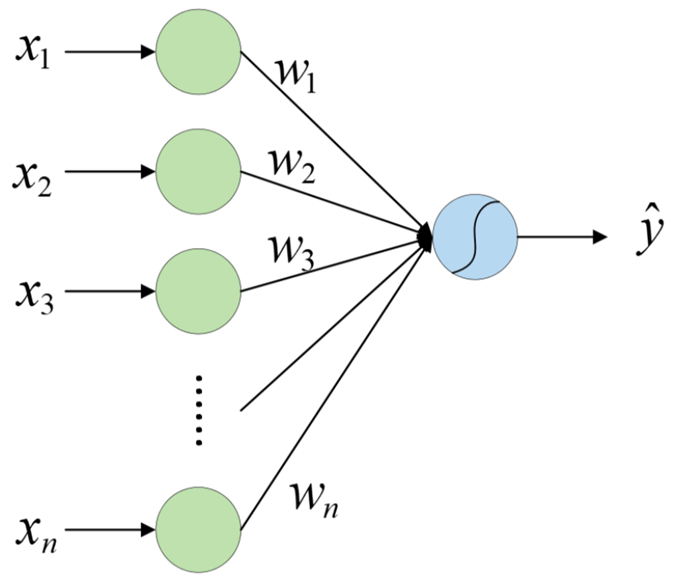
可以看出,逻辑回归本质上也是一个单层的神经网络。可以通过下方示意图来对上式中的模型进行表示。其中,输出层的曲线就表示这个映射函数。
同线性回归一样也需要通过一种间接的方式,即通过目标函数来刻画预测标签(Label)与真实标签之间的差距。当最小化目标函数后,便可以得到需要求解的参数和 。对于逻辑回归来说可以通过最小化以下目标函数来求解模型参数
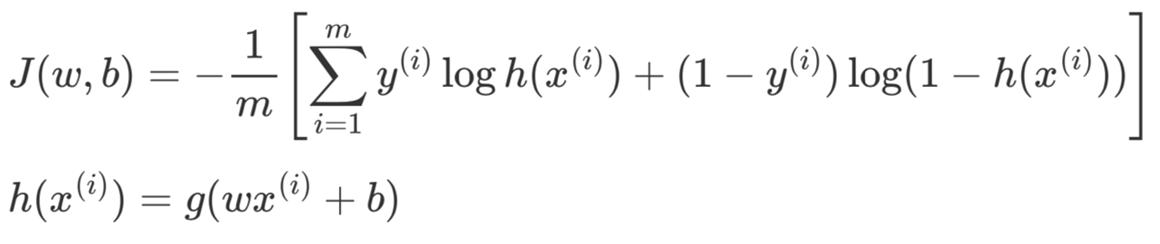
其中,表示样本总数, 表示第i个样本, 表示第个样本的真实标签,取值为0或1, 表示第个样本为正类的预测概率。当函数取得最小值的参数w ̂和b ̂ ,也就是要求的目标参数。
3.从二分类到多分类
在实际情况中,绝大多数任务场景都不会是一个简单的二分类任务。通常情况下在用逻辑回归处理多分类任务时,都会采取一种称为One-vs-all(也叫作 One-vs-rest)的方法。
One-vs-all策略的核心思想是每次将其中一个类别的样本和剩余其它类的所有样本两者看作一个二分类任务进行模型训练,最后在预测过程中选择输出概率值最大那个模型对应的类别作为该样本点的所属类别。
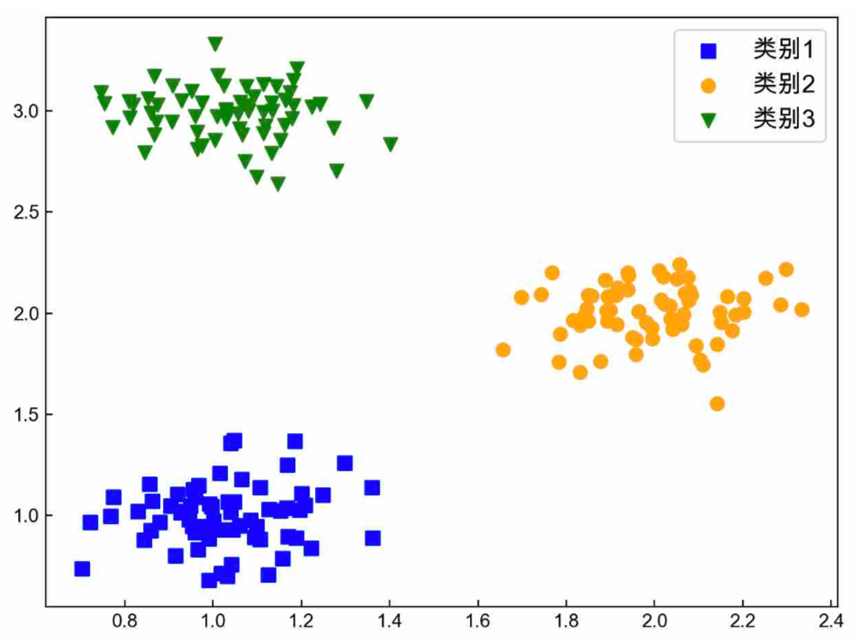
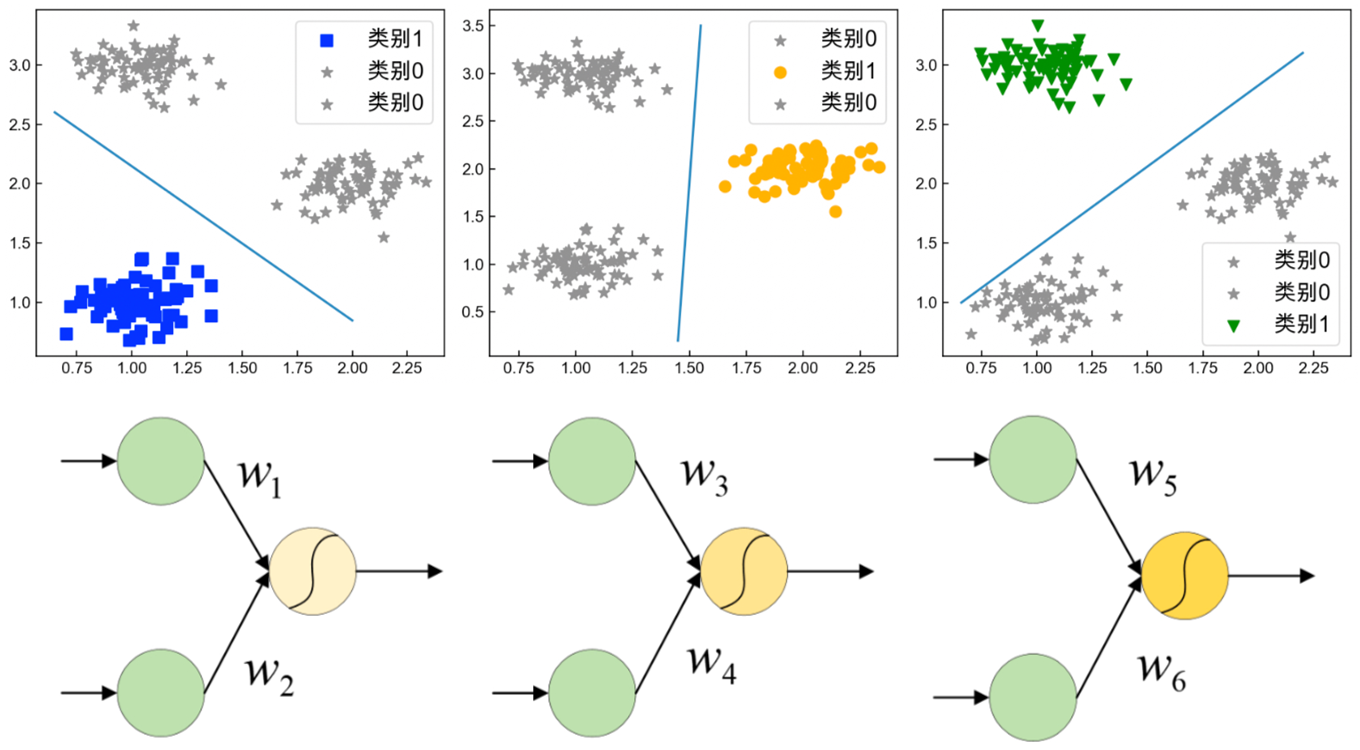
如图3.1为一个三分类的数据集,One-vs-all策略的核心是每次将其中一个类别的样本和剩余其它类的所有样本看作一个二分类任务进行模型训练如图3.2所示最后在预测过程中选择输出概率值最大的那个模型对应的类别作为该样本点的所属类别。
因此,可以建立3个二分类模型、和来完成整个3分类任务。
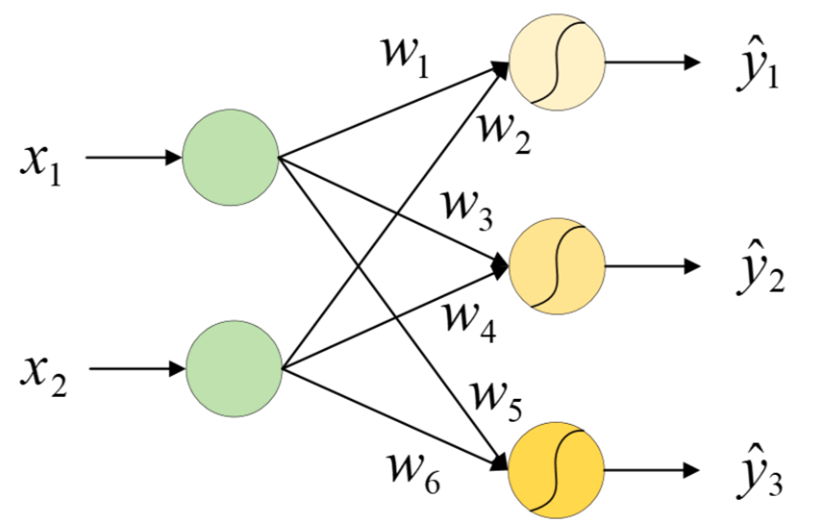
进一步可以简化为下图所示的形式。在这种条件下,模型训练时的标签将会被重新编码为另外一种形式。例如有5个样本,其类别编号分别为0、0、1、2、1,那么第1个样本的标签将被编码[1,0,0];第2个为[1,0,0];后续3个依次为[0,1,0]、[0,0,1]和[0,1,0],以此来与上面的3个输出计算损失。这种编码在深度学习中被称为独热(One-hot)编码。
4.Softmax回归
要将输出视为概率,我们必须保证在任何数据上的输出都是非负的且总和为1。如果有一种方法将输出层的置信值进行归一化,使得大小关系不变但所有结果相加等于1,那么便可以将整个输出结果视为该样本属于各个类别的概率分布。例如将[0.8,0.7,0.9]归一化成[0.33,0.30,0.37]。Softmax函数就是这样做的。
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。 为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。如下式:
同逻辑回归一样,对于图3.1中的三分类模型来说,Softmax回归首先进行各个特征之间的线性组合,然后再归一化处理。
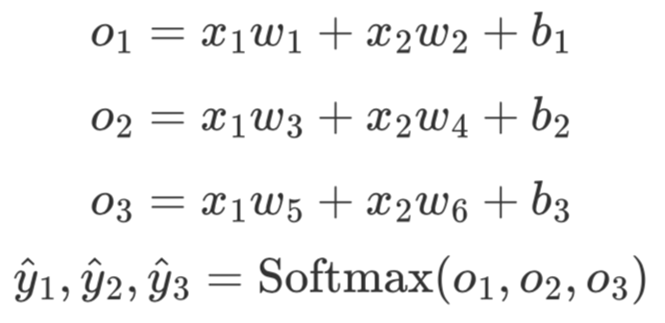
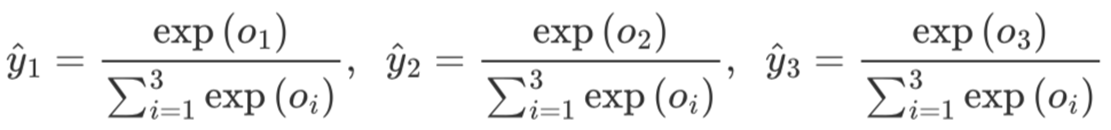
在经过,归一化过程后,可以看出,并且,即是一个合法的概率分布。最后通过不同类别的输出概率值的大小便能判断每个样本的所属类别。
交叉熵损失(损失函数-对数似然)
对于多分类任务来说可以通过衡量两个概率分布之间的相似性,即交叉熵(Cross Entropy)来构建目标函数,并通过梯度下降算法对其进行最小化从而求解得到模型对应的权重参数,即
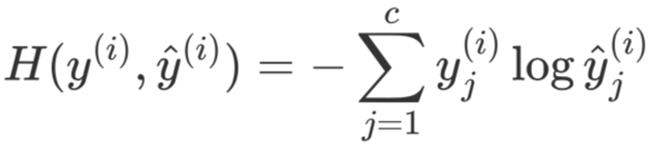
其中和y ̂^{(i)}分别表示第i个样本的真实概率分布和预测概率分布,和y ̂_j^{(i)}分别表示第i个样本第个类别对应的概率值,表示分类类别数,表示取自然对数。因此,对于包含有m个样本的训练集来说,其损失函数为
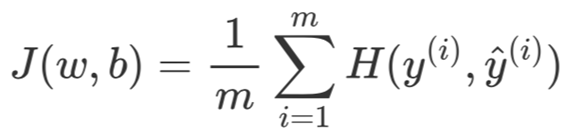
其中,和表示整个模型的所有参数,同时称其为交叉熵损失函数。
最后,这里有两点值得注意:
1.回归模型一般来讲是指对连续值进行预测的一类模型而分类模型则是指对离散值(类标)进行预测的一类模型,但逻辑回归和Softmax回归例外;
2.Softmax回归也是一个单层神经网络且直接对各个原始特征的线性组合进行归一化操作,但是Softmax这一操作却可以运用到每个神经网络的最后一层,而这也是深度学习中分类模型的标准操作。
5.Softmax回归的简洁实现
由于在深度学习中训练集的数量巨大很难一次同时计算所有权重参数在所有样本上的梯度,因此可以采用随机梯度下降(Stochastic Gradient Descent)或者是小批量梯度下降(Mini-batch Gradient Descent)来解决这个问题。相比于梯度下降算法在所有样本上计算得到目标函数关于参数的梯度然后再进行平均,随机梯度下降算法的做法是每次迭代时只取一个样本来计算权重参数对应的梯度。由于随机梯度下降是基于每个样本进行梯度计算,所以在迭代过程中每次计算得到的梯度值抖动很大,因此在实际情况中我们会每次选择一小批量的样本来计算权重参数的梯度,而这个批量的大小在深度学习中就被称为批大小(Batch Size)。
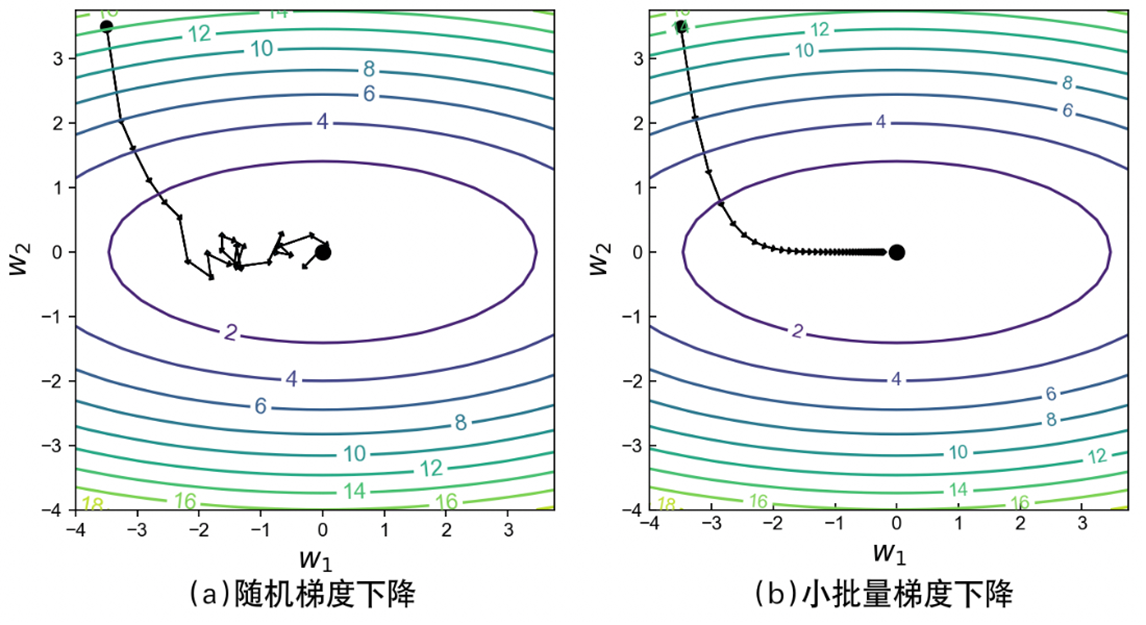
如图所示,环形曲线表示目标函数对应的等高线,左右两边分别为随机梯度下降算法和梯度下降算法求解参数w_1和w_2的模拟过程。从左侧的优化过程可以看出,尽管随机梯度下降算法最终也能近似求解得到最优解,但是在整个迭代优化过程中梯度却不稳定,极有可能导致陷入局部最优解当中。
5.1 DataLoader使用
在PyTorch中可以借助DataLoader模块来快速完成小批量数据的迭代生成。
1 | |
5.2 nn.CrossEntropyLoss()使用
在分类任务中会使用交叉熵来作为目标函数,且计算交叉熵损失之前需要对预测概率进行Softmax归一化。在PyTorch中可以借助nn.CrossEntropyLoss()模块来一次完成这两步计算过程。
1 | |
完整代码如下:
1 | |
6.手写体分类实现
pytorch实现
1 | |
从0实现多层神经网络的手写体分类
1 | |
参考
王成、黄晓辉——《跟我一起学深度学习》
李沐——《动手学深度学习》