学习笔记 — 机器人操作综述:重点关注 VLA(视觉-语言-动作) 方法
学习笔记 — 机器人操作综述:重点关注 VLA(视觉-语言-动作) 方法
本文基于 《Towards a Unified Understanding of Robot Manipulation: A Comprehensive Survey》,全面总结了机器人操作领域的最新研究成果,特别是围绕 VLA(Vision-Language-Action) 方法展开,深入分析了其在机器人操作中的应用与挑战。本文将详细讲解 VLA 方法的背景、关键技术、挑战、应用以及未来方向。
1. 引言
机器人操作是具身智能领域的核心任务之一,涉及感知、规划和控制的综合应用。随着计算机视觉和自然语言处理的进展,机器人操作已经进入了一个多模态交互的新时代,其中 VLA(视觉-语言-动作) 方法因其跨视觉和语言的能力,成为机器人操作的重要方向。
传统的机器人操作方法往往通过感知输入和规则来生成动作,而VLA 则通过多模态输入(视觉、语言)来生成动作,这使得机器人能够理解更为复杂的任务,特别是自然语言指令,并能够在动态和不确定的环境中灵活执行。
2. 机器人操作的背景
2.1 机器人硬件平台
机器人操作所依赖的硬件平台决定了机器人的任务执行能力,不同的硬件系统适用于不同的操作任务。常见的机器人平台包括:
- 单臂机器人(Single-arm Robots):如 KUKA LBR iiwa、Franka Panda,适用于简单的物体抓取和放置。
- 双臂机器人(Bimanual Robots):如 Franka Panda Dual Arm、ABB YuMi,适用于复杂的双手协作任务。
- 灵巧手(Dexterous Hands):如 Robotiq Dexterous Gripper,用于高精度的抓取与操作。
- 移动平台(Mobile Robots):如 Stretch、TIAGo,能够在复杂环境中移动并执行任务。
- 四足机器人(Quadrupedal Robots):如 Boston Dynamics Spot,适用于动态环境中的移动操作任务。
- 人形机器人(Humanoid Robots):如 Unitree GO1、Atlas,模拟人类的运动和操作。
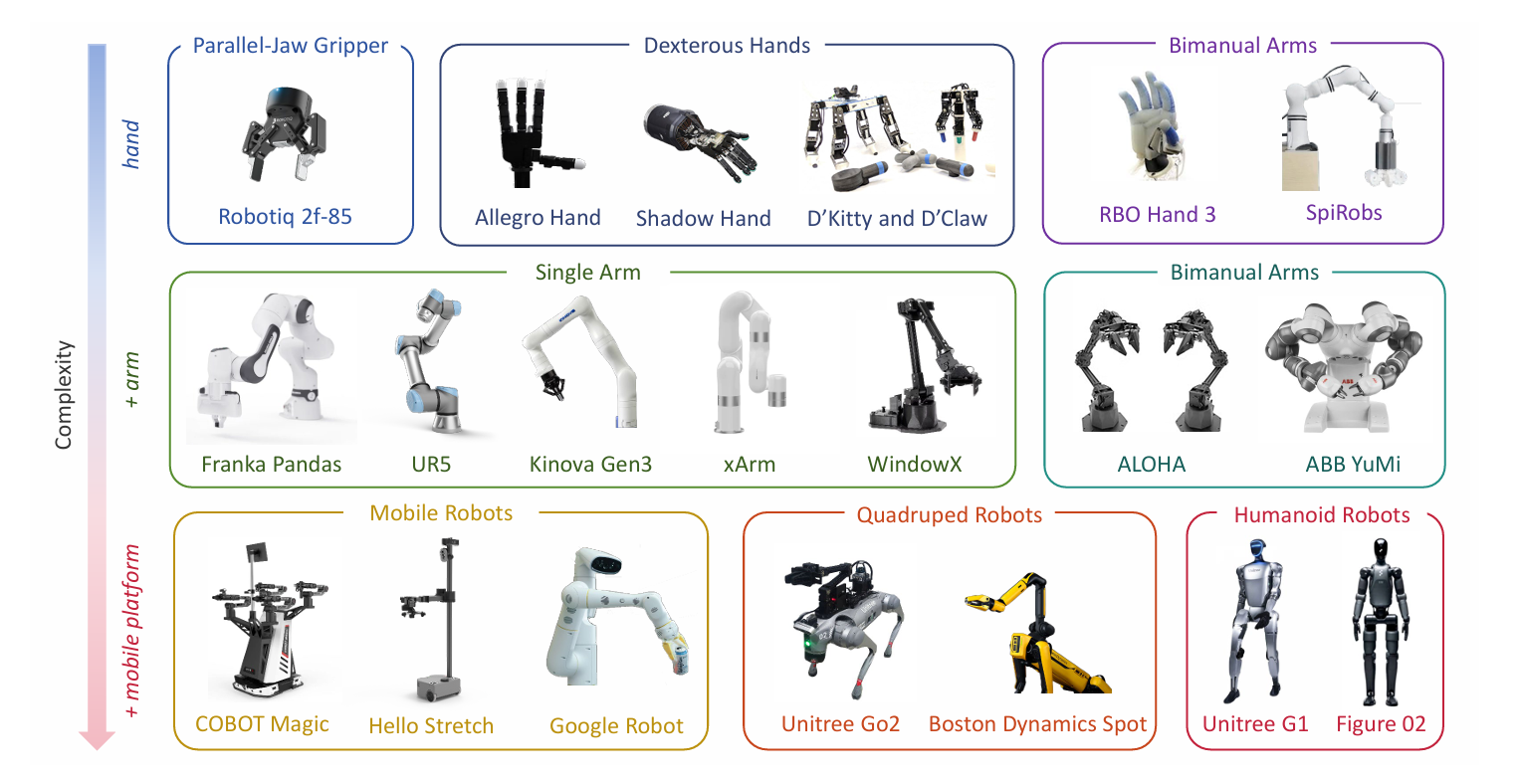
这些平台为机器人操作提供了多样的物理支持,每种平台都具有其独特的任务执行能力。
2.2 机器人操作的控制方法
机器人操作的控制方法可以分为两大类:
- 非学习控制(Non-learning Control):基于规则的控制方法,通常通过数学模型、优化和规划来执行任务。比如插值规划、采样规划和优化规划等。
- 基于学习的控制(Learning-based Control):通过学习算法(如强化学习、模仿学习)从数据中学习操作策略,适应复杂和动态环境。
VLA 方法属于基于学习的控制方法,通过多模态输入(视觉和语言)直接学习并执行任务。VLA 的核心优势在于其能够处理复杂的输入和任务,实现灵活的、多样化的操作。
3. 机器人操作任务与方法
3.1 机器人操作任务的分类
根据任务的难度和要求,机器人操作任务可以分为以下几类:
- 抓取(Grasping):机器人需要识别物体并执行抓取任务。这是机器人操作中最基础也是最常见的任务之一。
- 基础操作(Basic Manipulation):如物体的移动、排序、插入、拉开等。
- 灵巧操作(Dexterous Manipulation):复杂的操作任务,通常需要更高的精度和复杂的控制策略,比如物品组装或使用工具。
- 软体操作(Soft Robotic Manipulation):涉及柔性物体(如布料、软体机器人等)的操作。
- 可变形物体操作(Deformable Object Manipulation):例如布料、绳索等物体的操作,要求机器人能够处理物体的动态变化。
- 移动操作(Mobile Manipulation):结合移动平台进行物体抓取、搬运等任务,常用于动态、复杂的环境中。
- 四足操作(Quadrupedal Manipulation):四足机器人进行的操作任务,能够在复杂、崎岖的环境中进行物体抓取和处理。
- 人形操作(Humanoid Manipulation):模拟人类动作的机器人操作,常用于需要高度灵活性的任务。
3.2 视觉-语言-动作(VLA)模型
VLA(Vision-Language-Action) 是将视觉和语言输入结合起来,通过端到端的模型直接生成机器人的操作动作。VLA 方法的关键在于通过自然语言指令和视觉感知来实现多模态感知和动作生成。
1. VLA的输入输出模型
- 视觉输入(Visual Input):来自环境的视觉信息,通常包括2D图像、RGB-D图像、点云数据或3D重建。
- 语言输入(Language Input):自然语言指令,通常是机器人要执行的任务描述。
- 输出(Output):机器人的控制动作,如抓取物体的位姿、物体移动的轨迹等。
2. VLA 的核心结构
- 视觉编码器(Visual Encoder):负责从视觉数据中提取特征。常用的编码器包括CNN、ViT(Vision Transformer)和自监督学习模型(如 DINO)。
- 语言编码器(Language Encoder):用于解析和理解输入的自然语言,常用BERT、GPT等语言模型。
- 融合模块(Fusion Module):将视觉和语言输入结合起来,常用的方法包括跨注意力(Cross-attention)机制或融合视觉与语言特征的Transformer架构。
- 策略网络(Policy Network):在多模态输入的基础上生成机器人控制动作,可能使用MLP、Transformer、Diffusion等网络进行动作解码。
3. VLA 方法的演变
- 早期的视觉-动作模型:最初的模型仅利用视觉信息生成动作,例如通过CNN将图像映射到动作指令。这些方法较为简单,处理的是基础任务,如抓取、放置。
- 视觉-语言-动作联合模型:随着语言理解模型的发展,VLA方法逐渐引入自然语言输入,结合视觉信息进行任务规划。此时,VLA 模型通过语言理解和视觉感知共同推导机器人的动作。
- 大规模预训练模型(如 PaLM-E 和 RT-2):这些预训练的大规模模型通过从大量的视觉、语言和动作数据中学习,能够更好地应对复杂的、跨任务的操作需求。它们的优势在于对任务指令的零样本泛化能力。
3.3 控制方法与任务的融合
VLA 模型不仅能够理解自然语言指令,还能在动态、复杂的环境中生成和执行任务。VLA 方法的优势在于:
- 多模态输入:通过融合视觉和语言信息,机器人能够更好地理解复杂任务,并在复杂环境中执行。
- 灵活性和适应性:VLA方法的策略生成能力使机器人能够适应动态和未知的环境,并执行不同类型的任务。
VLA 方法与传统控制方法的比较:
- VLA 方法通过多模态感知生成动作,而传统方法往往依赖于感知与规划模型进行任务执行。
- 传统方法(如采样规划、优化控制)适用于已知环境,而 VLA方法 更适合不确定环境中的任务。
4. 持续挑战与瓶颈
尽管 VLA 方法展示了巨大的潜力,但依然存在一些挑战:
- 数据收集瓶颈:高质量的视觉-语言-动作数据集依然稀缺,尤其是在复杂和多样化的任务环境下。
- 泛化能力:如何在不同的机器人平台、任务、环境中实现有效的零样本泛化是一个巨大的挑战。
- 多模态融合问题:在处理多模态信息时,如何有效融合视觉和语言信息,特别是在动态复杂环境中,仍然是一个挑战。
- 计算资源与实时性:大规模的VLA模型计算开销大,如何确保其在实际应用中的实时性和效率是亟待解决的问题。
5. 应用与未来方向
5.1 应用方向
- 家庭助理机器人:通过语言指令和视觉感知,机器人能够完成日常任务,如清洁、物品递送等。
- 工业自动化:在制造业中,VLA方法能够帮助机器人完成组装、检测等任务,提升生产效率。
- 人机协作:VLA系统能够提高人类和机器人的协同工作能力,特别是在复杂的任务环境中。
5.2 未来方向
- 机器人大脑:构建通用的机器人大脑,融合语言理解、视觉感知和动作执行,实现跨任务的泛化能力。
- 多模态感知:除了视觉和语言外,未来的VLA模型将会集成更多的感知模态,如触觉、声音等,以增强机器人与环境的交互能力。
- 自监督与零样本学习:减少对大规模标注数据的依赖,通过自监督学习和零样本学习提升VLA模型的泛化能力。
6. 结论
VLA方法在机器人操作中展现了巨大的潜力,能够通过视觉和语言的多模态输入,生成机器人操作的动作。随着大规模预训练模型和自监督学习的进展,VLA系统将能够在更加复杂和动态的环境中执行任务。然而,数据瓶颈、泛化能力和计算效率等问题仍然是当前研究的关键挑战。未来的研究将继续推进VLA技术,提升机器人在现实世界中的适应性和效率。