OpenVla复现
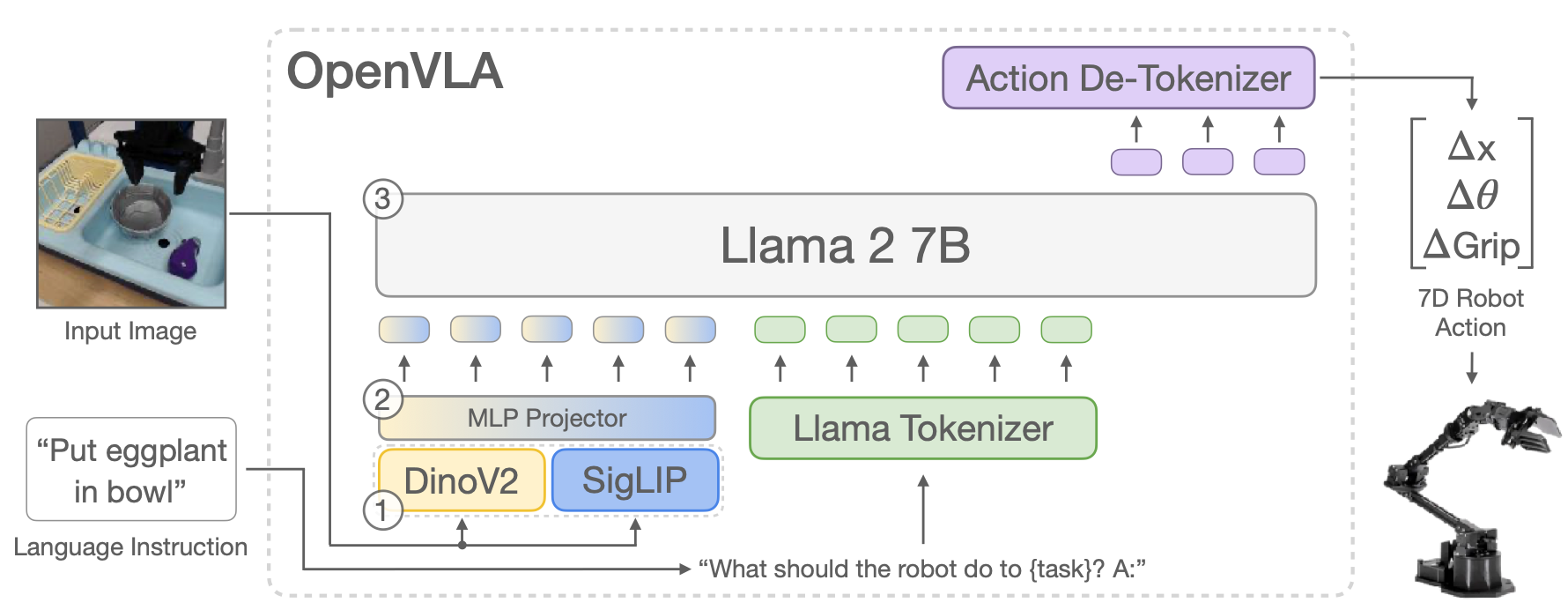
这份文档为记录了详尽的 OpenVLA (Open-Source Vision-Language-Action) 模型推理任务复现记录。OpenVLA 是基于 Llama 2 和 DINOv2/SigLIP 的视觉-语言-动作模型,专为机器人控制任务设计。
这份记录模拟了在 Linux 服务器环境下的完整操作流程,涵盖了从环境配置到最终动作输出的每一个细节。
实验记录:OpenVLA-7B 模型推理复现
日期: 2025-11-28
实验目的: 验证 OpenVLA-7B 模型在给定图像和指令下的推理能力,并解析输出的动作(Action)。
参考项目:
openvla/openvla-7b
openvla
1. 硬件与环境准备 (Hardware & Environment)
OpenVLA-7B 是一个 70 亿参数的模型。为了流畅运行,显存(VRAM)是关键瓶颈。
| 硬件/软件 | 配置说明 | 备注 |
|---|---|---|
| GPU | NVIDIA RTX 3090 (24GB) | 若显存 < 16GB,需使用 4-bit 量化 |
| CPU/RAM | 32GB+ RAM | 模型加载时需要较大的系统内存 |
| OS | Ubuntu 20.04 | 推荐 Linux 环境 |
| Python | 3.10 | 避免版本过低导致的库冲突 |
| CUDA | 12.1 | 配合 PyTorch 版本 |
1.1 创建虚拟环境
建议使用conda进行环境隔离:
1 | |
1.2 安装核心依赖
OpenVLA 依赖 transformers 库的最新功能以及 bitsandbytes (用于量化)。
1 | |
2.LIBERO下载
LIBERO旨在研究多任务和终身机器人学习问题中的知识转移。成功解决这些问题需要对对象/空间关系的声明性知识以及关于运动/行为的程序性知识。LIBERO提供:
- 一个程序生成流水线,原则上可以生成无限数量的作任务。
- 130个任务被分为四个任务套件:LIBERO-空间、LIBERO-对象、LIBERO-目标和LIBERO-100。前三个任务套件具有受控分布转移,意味着它们需要传输特定类型的知识。相比之下,LIBERO-100包含100个作任务,这些任务需要传输纠缠知识。LIBERO-100进一步细分为LIBERO-90用于预训练策略,LIBERO-10用于测试智能体的下游终身学习性能。
- 五个研究课题。
- 三种视觉运动政策网络架构。
- 三种终身学习算法,具有顺序微调和多任务学习基线。
2.1 LIBERO配置
克隆并安装LIBERO仓库:
1 | |
此外,还要安装其他必需的软件包:
1 | |
2.2 启动LIBERO评估
项目Markdown中说明了,他们通过LoRA(r=32)独立对四个LIBERO任务组进行了微调:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-10(也称为LIBERO-Long)。 四个检查点可在Hugging Face上查看:
- OpenVLA/OpenVLA-7B-微调-libero-spatial
- OpenVLA/OpenVLA-7B-Finetuned-Libero-Object
- OpenVLA/OpenVLA-7B-微调-libero-goal
- OpenVLA/OpenVLA-7B-微调-libero-10
libero环境下复现包含4个套件,每个套件10个任务,每个任务50轮推理,推理结束后⾃动开始下⼀个任务的推理。这里我们选择openvla-7b-finetuned-libero-spatial
2.2.1模型下载
方式一:官网下载
方式二:modelscope下载
1 | |
2.2.2 启动
1 | |
5.结果
| ✅ 成功测试1 | ✅ 成功测试2 | ✅ 成功测试3 |
|---|---|---|
 |
 |
 |
| 拿起放在木质橱柜上的那个黑色碗,并将它放到盘子中 | 拿起放在小烤碗旁边的那个黑色碗,并将它放在盘子中 | 拿起小烤碗旁边的黑色碗,并把它放到盘子中 |
| ✅ 成功测试4 | ✅ 成功测试5 | ✅ 成功测试6 |
 |
 |
 |
| 拿起饼干盒旁边的黑色碗,并将它放到盘子中 | 拿起放在饼干盒上的黑色碗,并把它放到盘子中 | 拿起木质橱柜最上面抽屉里的黑色碗,并把它放到盘子中 |
以上的六个测试用例都是成功的测试用例,接下来再展示几个失败的测试用例
| ❌ 失败测试1 | ❌ 失败测试2 | ❌ 失败测试3 |
|---|---|---|
 |
 |
 |
| 拿起放在饼干盒上的黑色碗,并将它放到盘子中 | 拿起炉子上的黑色碗,并将它放到盘子中 | 拿起木质橱柜上的黑色碗,并将它放到盘子中 |
| 失败原因:虽然成功的放到了盘子中,但是模型没有停止输出,导致仿真环境的 Step 达到最大次数,发生了截断 | 失败原因:对炉子上的黑色碗的位置判断不够准确,当机械臂还没有移动到准确的位置时,就执行了抓取动作 | 失败原因:虽然成功的放到了盘子中,但是模型没有停止输出,导致仿真环境的 Step 达到最大次数,发生了截断 |
如果你看不到 gif ,请科学上网 ✅
6. 踩坑与故障排除 (Troubleshooting)
在复现过程中,以下是遇到的问题及解决方案:
6.1 找不到libero模块
报错:No model named ‘libero’
这个报错的核⼼原因是:Python解释器在当前 libero 包(虽然你安装了 openvla 环境的「模块搜索路径」中,找不到 libero-0.1.0 ,但安装路径 /data/sjj/LIBERO 没被当前环境 识别)。
将路径添加到python环境即可
1 | |
6.2 网络连接超时(*)
1 | |
1.将代码中模型加载路径改为本地模型路径。(推荐、简单)
2.科学上网
6.3 Flash Attention 报错
Flash Attention安装报错,将镜像下载到本地,再进行安装注意下载镜像要检查python、torch、cuda的版本一定要对应。
1 | |
7. 总结 (Summary)
下一步计划:
尝试 OpenVLA 微调(Fine-tuning) 的复现,并且尝试将此模型部署到其它机器人中。